AFL 源码学习
最近学习了由Google安全工程师Michał Zalewski开发的一款开源fuzzing测试工具American Fuzzy Lop。这里总结一下阅读源码中的收获和使用的相关技巧。
AFL安装和使用
AFL的安装非常简单,仅仅需要下载源码然后进行编译安装。1
2
3
4
5wget http://lcamtuf.coredump.cx/afl/releases/afl-latest.tgz
tar xvf afl-latest.tgz
cd afl-*
$ make && make install
$ make install
编译目标程序
AFL有afl-gcc和llvm两种模式
1.afl-gcc
AFL提供了两种常见编译器的wrapper,afl-gcc和afl-g++,在进行编译的时候,仅需指定编译器为afl-gcc/afl-g++即可1
2./configure CC="afl-gcc"
./configure CXX="afl-g++"
2.llvm
使用llvm模式进行编译可以提高fuzzing的速率,在llvm_mode目录中进行编译安装,之后使用afl-clang-fast构建目标程序。1
2
3cd llvm_mode
export LLVM_CONFIG=`which llvm-config` && make && cd ..
./configure --disable-shared CC="afl-clang-fast" or CXX="afl-clang-fast++"
运行Fuzzing
afl-fuzz程序是AFL进行fuzzing的主程序,安装成功后使用afl-fuzz命令便可查看相关命令。1
2
3
4
5
6
7
8
9root@localhost:~# afl-fuzz
afl-fuzz 2.52b by <[email protected]>
afl-fuzz [ options ] -- /path/to/fuzzed_app [ ... ]
Required parameters:
-i dir - input directory with test cases
-o dir - output directory for fuzzer findings
fuzz前需要进行的配置工作 (To avoid having crashes misinterpreted as timeouts, please log in as root and temporarily modify /proc/sys/kernel/core_pattern.)1
echo core >/proc/sys/kernel/core_pattern
运行fuzz程序1
afl-fuzz -i afl_in -o afl_out /path/to/target [params]
- -i:输入测试用例
- -o:输出结果
- -t:设置程序执行的超时
- -d:quick & dirty 模式
输出结果
运行fuzzing后,会在输出文件夹中产生三个文件夹queue,crashes,hangs
- queue: 每个文件代表了afl-fuzz在fuzzing过程中获得的所有路径,每条路径不重复并且每条新路径都被修剪(trim)过
- crashed: 会导致目标程序crash的输入用例
- hangs: 导致目标程序超时的输入用例
AFL工作流程
- afl_fuzz的main函数会解析用户输入命令,检查环境变量的设置、输入输出路径、目标文件。程序定义了结构体queue_entry链表维护fuzz中使用的文件。
- 函数perform_dry_run()会使用初始的测试用例进行测试,确保目标程序能够正常执行,生成初始化的queue和bitmap。
1
2
3
4
5
6
7
8
9
10
11
12perform_dry_run(char** argv) {
struct queue_entry* q = queue;
while (q) {
//调用calibrate_case()函数对用例进行测试,验证输入用例是否会引发目标程序crash
res = calibrate_case(argv, q, use_mem, 0, 1);
switch (res) {
case FAULT_NONE:
case FAULT_TMOUT:
case FAULT_CRASH:
}
}
} - 函数 cull_queue() 会对初始队列进行筛选(更新favored entry)。遍历top_rated[]中的queue,然后提取出发现新edge的entry,并标记为favored,使得在下次遍历queue时,这些entry能获得更多执行fuzz的机会。
这里使用greedy来进行筛选。首先初始化temp_v(previously-unseen bytes)并且设置queue_entry中的所有favored为0(q->favored = 0)。之后判断是否在top_rated中并且有被temp_v命中的bitmap,如果是便将其设置为favored(top_rated[i]->favored = 1)。
**More Detail:** 这里需要结合update_bitmap_score()进行理解。update_bitmap_score在trim_case和calibrate_case中被调用,用来维护一个最小(favored)的测试用例集合(top_rated[i])。这里会比较执行时间*种子大小,如果当前用例更小,则会更新top_rated。
1
2
3
4
5
6
7
8
9
10
11
12
e.g. tuple t0,t1,t2,t3,t4;seed s0,s1,s2 初始化temp_v=[1,1,1,1,1]
s1可覆盖t2,t3 | s2覆盖t0,t1,t4,并且top_rated[0]=s2,top_rated[2]=s1
开始后判断temp_v[0]=1,说明t0没有被访问
top_rated[0]存在(s2) -> 判断s2可以覆盖的范围 -> trace_mini=[1,1,0,0,1]
更新temp_v=[0,0,1,1,0]
标记s2为favored
继续判断temp_v[1]=0,说明t1此时已经被访问过了,跳过
继续判断temp_v[2]=1,说明t2没有被访问
top_rated[2]存在(s1) -> 判断s1可以覆盖的范围 -> trace_mini=[0,0,1,1,0]
更新temp_v=[0,0,0,0,0]
标记s1为favored
此时所有tuple都被覆盖,favored为s1,s2
- 进入while(1)开始fuzz循环
- 进入循环后第一部还是 cull_queue() 对queue进行筛选
- 判断queue_cur是否为空,如果是,则表示已经完成对队列的遍历,初始化相关参数,重新开始遍历队列
- fuzz_one() 函数会对queue_cur所对应文件进行fuzz
1
2
3
4
5
6
7
8
9
10
11
12
13[1] 根据是否有pending_favored和queue_cur的情况按照概率进行跳过
有pending_favored, 对于fuzz过的或者non-favored的以概率99%跳过
无pending_favored,95%跳过fuzzed&non-favored,75%跳过not fuzzed&non-favored,不跳过favored (跳过概率的宏定义在config.h中)
[2] fd加载测试用例,如果之前calibrate失败,则重新进行calibrate_case()
[3] 修剪测试用例,减小input大小
[4] calculate_score(queue_cur)得到performance score,如果该queue已经完成deterministic fuzzing,则直接跳到havoc阶段
[5] 接下来会进行四种deterministic的变异
bitfilp:按位翻转,1变为0,0变为1
arithmetic:整数加/减算术运算
interest:把一些特殊内容替换到原文件中
dictionary:把自动生成或用户提供的token替换/插入到原文件中
[6] havoc 多种变异方式的组合
[7] splice:拼接,2个seed进行拼接,并进行havoc - 判断是否结束,更新queue_cur和current_entry
1
2queue_cur = queue_cur->next;
current_entry++; - 当队列中的所有文件都经过变异测试了,则完成一次”cycle done”。整个队列又会从第一个文件开始,再次继续进行变异,不过与第一次变异不同的是,因为没有随机性,这一次变异就不需要再进行deterministic fuzzing了。
afl-fuzz.c
1 | int main(int argc, char** argv) { |
AFL变异
- AFL中实现了6种变异方式:
- bitfilp:按位翻转,1变为0,0变为1
按位翻转,1变为0,0变为1。AFL中会根据翻转量/步长进行多种不同的翻转,按照顺序依次为:
bitflip 1/1,每次翻转1个bit,按照每1个bit的步长从头开始
这里也会对syntax tokens进行检测
bitflip 2/1,每次翻转相邻的2个bit,按照每1个bit的步长从头开始
bitflip 4/1,每次翻转相邻的4个bit,按照每1个bit的步长从头开始
bitflip 8/8,每次翻转相邻的8个bit,按照每8个bit的步长从头开始,即依次对每个byte做翻转
bitflip 16/8,每次翻转相邻的16个bit,按照每8个bit的步长从头开始,即依次对每个word做翻转
bitflip 32/8,每次翻转相邻的32个bit,按照每8个bit的步长从头开始,即依次对每个dword做翻转 - arithmetic:整数加/减算术运算
arith 8/8,每次对8个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个byte进行整数加减变异
arith 16/8,每次对16个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个word进行整数加减变异
arith 32/8,每次对32个bit进行加减运算,按照每8个bit的步长从头开始,即对文件的每个dword进行整数加减变异
加减运算的相关设置在config.h定义,由于整数存在大端序和小端序两种表示方式,AFL会贴心地对这两种整数表示方式都进行变异。此外,AFL会智能的跳过某些arithmetic:
第一种情况就是前面提到的effector map:如果一个整数的所有bytes都被判断为“无效”,那么就跳过对整数的变异。
第二种情况是之前bitflip已经生成过的变异:如果加/减某个数后,其效果与之前的某种bitflip相同,那么这次变异肯定在上一个阶段已经执行过了,此次便不会再执行。 - interest:把一些特殊内容替换到原文件中
interest 8/8,每次对8个bit进替换,按照每8个bit的步长从头开始,即对文件的每个byte进行替换
interest 16/8,每次对16个bit进替换,按照每8个bit的步长从头开始,即对文件的每个word进行替换
interest 32/8,每次对32个bit进替换,按照每8个bit的步长从头开始,即对文件的每个dword进行替换其中interest value的值在config.h已经设定好。可以看到,用于替换的基本都是可能会造成溢出的数;与之前相同,effector map仍然会用于判断是否需要变异; - dictionary:把自动生成或用户提供的token替换/插入到原文件中
user extras (over),从头开始,将用户提供的tokens依次替换到原文件中
user extras (insert),从头开始,将用户提供的tokens依次插入到原文件中
auto extras (over),从头开始,将自动检测的tokens依次替换到原文件中
tokens:在进行bitflip 1/1变异时,对于每个byte的最低位(least significant bit)翻转还进行了额外的处理:如果连续多个bytes的最低位被翻转后,程序的执行路径都未变化,而且与原始执行路径不一致,那么就把这一段连续的bytes判断是一条token。 - havoc 多种变异方式的组合
随机选取某个bit进行翻转
随机选取某个byte,将其设置为随机的interesting value
随机选取某个word,并随机选取大、小端序,将其设置为随机的interesting value
随机选取某个dword,并随机选取大、小端序,将其设置为随机的interesting value
随机选取某个byte,对其减去一个随机数
随机选取某个byte,对其加上一个随机数
随机选取某个word,并随机选取大、小端序,对其减去一个随机数
随机选取某个word,并随机选取大、小端序,对其加上一个随机数
随机选取某个dword,并随机选取大、小端序,对其减去一个随机数
随机选取某个dword,并随机选取大、小端序,对其加上一个随机数
随机选取某个byte,将其设置为随机数
随机删除一段bytes
随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入一段随机选取的数
随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是替换成一段随机选取的数
随机选取一个位置,用随机选取的token(用户提供的或自动生成的)替换
随机选取一个位置,用随机选取的token(用户提供的或自动生成的)插入 - splice:拼接,2个seed进行拼接,并进行havoc
calculate_score()
根据execution speed, bitmap size, handicap, input depth来对case评分,用来调整在havoc阶段的用时。使得执行时间短,代码覆盖高,新发现的,路径深度深的case拥有更多havoc变异的机会。
AFL插桩
AFL插桩部分源码主要有三个,afl-gcc.c、afl-as.h、afl-as.c
afl-gcc.c
该文件可以看做是一个gcc的wrapper,同时也会完成对用户指令的解析,然后将结果传递给gcc,完成目标程序的编译。
main中主要调用了三个函数:1
2
3find_as(argv[0]); //找到gcc/clang/llvm编译器
edit_params(argc, argv); //处理参数
execvp(cc_params[0], (char**)cc_params); //执行解析后的命令
其中find_as()会检查编译器的搜索路径(AFL_PATH),edit_params()根据用户的编译需求对gcc命令进行修改,最后execvp()执行编译命令,生成目标文件。
可以打印cc_params来查看实际执行的命令1
2for (int i = 0; i < cc_par_cnt; i ++)
SAYF(" %s", cc_params[i]);
运行结果为:
Origin: /root/afl/afl-2.52b/afl-gcc -g -o hello hello.c
Modified: gcc -g -o hello hello.c -B /root/afl/afl-2.52b -g -O3 -funroll-loops -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1
afl-gcc实际执行了gcc编译命令,但是增加了几条命令。
-B \<directory>: Add \<directory> to the compiler’s search paths
插桩流程
从source code -> executable file要经过预处理(preprocessing))->编译(compilation)->汇编(assembly)->连接(linking)的流程。
- 编译预处理程序对源文件进行预处理,生成预处理文件(.i文件)
- 编译插桩程序对.i文件进行编译,生成汇编文件(.s文件)
afl在这一步骤会对目标程序进行插桩 - 汇编程序(as)对.s文件进行汇编,生成目标文件(.o文件)
- 链接程序(ld)对.o文件进行连接,生成可执行文件(.out/.elf文件)
compiler (language -> assembly), assembler (assembly -> object code), linker (object code -> executable/library)
在Linux机器上使用gcc进行编译的时候,默认会使用GNU as作为汇编器,这里使用-B参数指定使用afl-as。之后afl-as读取并且parse输入的.s文件,添加instrumentation trampoline和main payload。
依旧可以打印出实际执行的命令进行观察:
as_origin: /usr/local/lib/afl/as –64 -o /tmp/cczZQfJ3.o /tmp/ccPZDPvs.s
as_modified: as –64 -o /tmp/cczZQfJ3.o /tmp/.afl-15696-1568785903.s
afl-as在插入完成后,还是会调用实际的as完成汇编。
afl-as.c
1 | int main(int argc, char** argv) { |
这里主要有几个步骤,首先是获得一个重要的参数AFL_INST_RATIO,即指令插入的速度。
edit_params会生成实际要执行的as命令。
在使用ASAN或MSAN的情况下,会将指令插入速度调慢。
之后就是实际进行的插桩(add_instrumentation)工作。
最后fork进程执行as命令完成汇编。
add_instrumentation()
1 | static void add_instrumentation(void) { |
根据程序中的注释,这里会匹配main函数,GCC中的branch label,clang中的branch label和conditional branches,然后插入相应指令。
trampoline
trampoline的源码定义在afl-as.h中,对应的有32位和64位两个版本。
在64位系统下,使用afl-gcc编译生成hello-word并且使用gdb进行反汇编结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21gdb-peda$ disassemble main
Dump of assembler code for function main:
0x00000000004006e0 <+0>: lea rsp,[rsp-0x98]
0x00000000004006e8 <+8>: mov QWORD PTR [rsp],rdx
0x00000000004006ec <+12>: mov QWORD PTR [rsp+0x8],rcx
0x00000000004006f1 <+17>: mov QWORD PTR [rsp+0x10],rax
0x00000000004006f6 <+22>: mov rcx,0xdf40
0x00000000004006fd <+29>: call 0x400838 <__afl_maybe_log>
0x0000000000400702 <+34>: mov rax,QWORD PTR [rsp+0x10]
0x0000000000400707 <+39>: mov rcx,QWORD PTR [rsp+0x8]
0x000000000040070c <+44>: mov rdx,QWORD PTR [rsp]
0x0000000000400710 <+48>: lea rsp,[rsp+0x98]
0x0000000000400718 <+56>: sub rsp,0x8
0x000000000040071c <+60>: mov esi,0x400cb4
0x0000000000400721 <+65>: mov edi,0x1
0x0000000000400726 <+70>: xor eax,eax
0x0000000000400728 <+72>: call 0x400680 <__printf_chk@plt>
0x000000000040072d <+77>: xor eax,eax
0x000000000040072f <+79>: add rsp,0x8
0x0000000000400733 <+83>: ret
End of assembler dump.
注意:GNU汇编器使用AT&T样式的语法,所以其中的源和目的操作数和Intel文档中给出的顺序是相反的。
可以看到afl插入了对应的64位trampoline汇编代码。结合afl-as.h中的代码分析,可以得知插入的汇编代码首先保存了rdx、rcx、rax寄存器的值。
这里分析一下“mov rcx,0xdf40”这条语句,这里的0xdf40实际上是一个随机数,用于定位执行到的代码块。在config.h中可以看到1
2
在默认宏定义下,MAP_SIZE为64K。在types.h文件中可以找到R(x)的宏定义:1
define R(x) (random() % (x))
回到afl-as.c文件1
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE));
这里的R(MAP_SIZE))即为0 ~ MAP_SIZE间的随机数(即本示例中的0xdf40)。
之后插入的这段汇编代码便会调用_afl_maybe_log(),调用完成后恢复寄存器。
结合afl-as.h中的源码可以更加直观的理解R(MAP_SIZE)的含义:1
2movq $0x%08x, %%rcx
call __afl_maybe_log
afl_maybe_log即为fork server需要进行的具体操作,这里可以理解插入的代码为afl_maybe_log(random() % MAP_SIZE),这里的随机性使得可以唯一定位程序运行的位置(不考虑碰撞的情况下)。
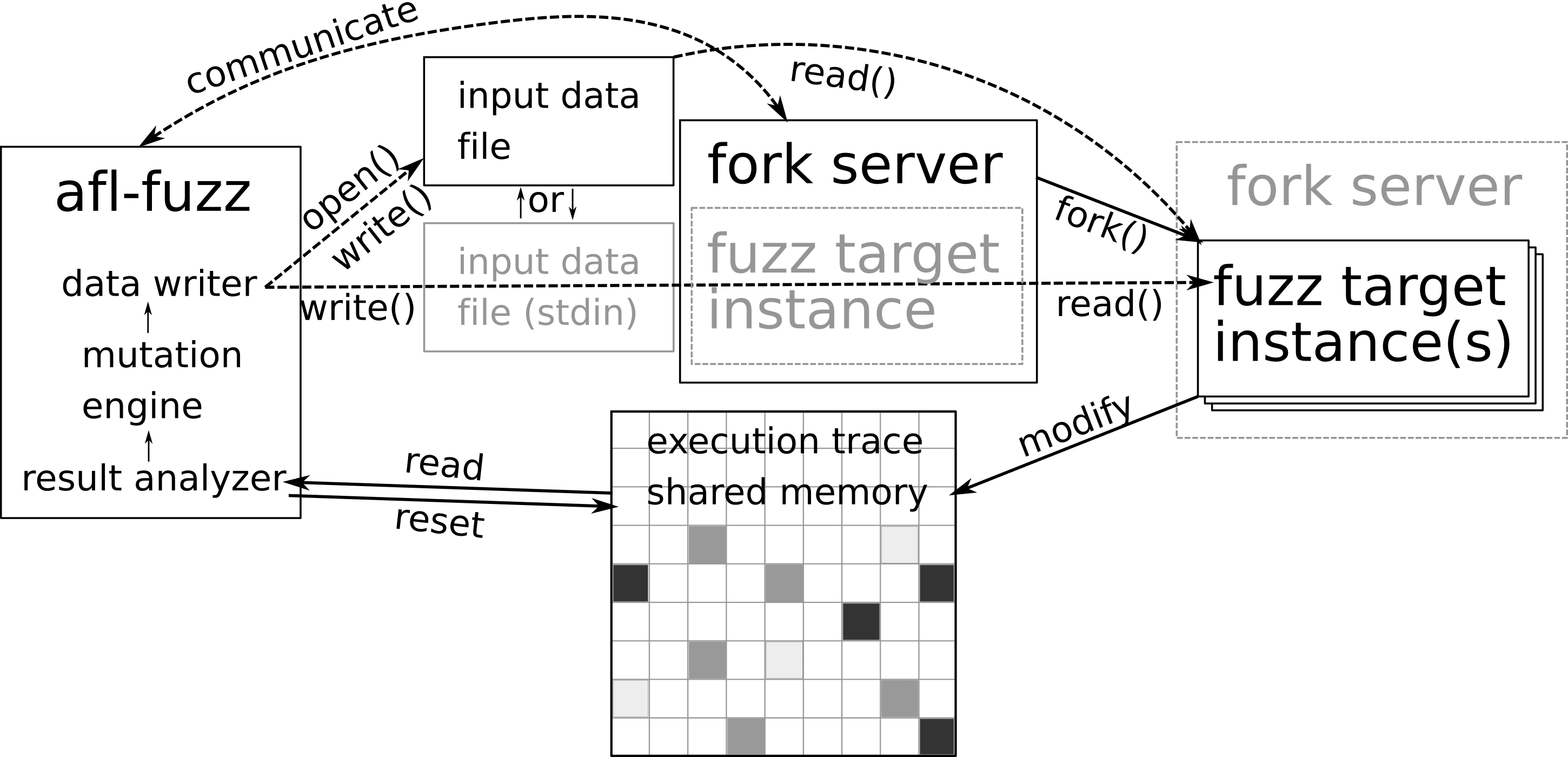
Fork Server
afl使用fork server来提高fuzz的速度,在目标程序编译成功后,需要使用afl-fuzz进行fuzz。这里afl会根据用户的原始输入,再进行一系列的mutate,然后将结果传入目标程序,并且分析程序运行是否正常。这里为了节约反复使用execve()加载目标程序造成的额外开销(载入目标文件和库、解析符号地址),afl实现了fork server来完成目标程序的反复执行。
afl作者在博客中提到,原本fork server的实现有两种思路:
[1] 实现一个ELF loader
[2] snapshot子进程
但是这两种实现在处理signal和file descriptors时会遇到困难。
结合之前的alf-fuzz进行分析,calibrate_case()函数会调用init_forkserver()来完成forkserver的初始化。1
2if (dumb_mode != 1 && !no_forkserver && !forksrv_pid)
init_forkserver(argv);
init_forkserver()
该函数主要会执行fork()得到父进程和子进程,父进程为afl-fuzz,子进程为forkserver。
主要步骤如下
- 创建2个管道:
ctl_pipe传递控制: 父进程写 -> 子进程读
st_pipe传递状态: 子进程写 -> 父进程读 - 调用fork()
- 子进程: 绑定输入流输出流到FORKSRV_FD
ctl_pipe[0] -> FORKSRV_FD 输入流
st_pipe[1] -> FORKSRV_FD + 1 输出流
execv(target_path, argv)创建新进程,执行目标程序。这里使用dup2来绑定绑定管道到FORKSRV_FD上
dup(oldfd) -> fcntl(oldfd, F_DUPFD, 0)
dup2(oldfd, newfd) -> close(oldfd);fcntl(oldfd, F_DUPFD, newfd);1
2
3
4if (!forksrv_pid) {
if (dup2(ctl_pipe[0], FORKSRV_FD) < 0) PFATAL("dup2() failed");
if (dup2(st_pipe[1], FORKSRV_FD + 1) < 0) PFATAL("dup2() failed");
execv(target_path, argv); - 父进程:主要做些错误处理相关的工作,通过管道读取子进程返回状态,来确定server是否正常运行起来了
1
2
3
4
5
6
7fsrv_ctl_fd = ctl_pipe[1];
fsrv_st_fd = st_pipe[0];
rlen = read(fsrv_st_fd, &status, 4);
if (rlen == 4) {
OKF("All right - fork server is up.");
return;
}fuzzer <-> fork_server
简化的流程图如下:
首先alf-fuzz会创建两个管道(init_forkserver()),然后会去执行afl-gcc编译出来的目标程序。结合之前的分析,目标程序的main函数位置已经被插桩,程序的控制流会交到_afl_maybe_log手中。如fuzz是第一次运行,则此时的程序便成为了fuzz server,之后运行的目标程序都是由该server fork出来的子进程。fuzz进行的时候,fuzz server会一直fork子进程,并且将子进程的结束状态通过pipe传递给afl-fuzz。
这里有几点需要注意:afl在这里利用了fork()的特性(creates a new process by duplicating the calling process)来实现目标程序反复执行。实际的fuzz server(_afl_maybe_log)由afl事先插桩在目标程序中,在进入main函数之前,fuzz server便会fork()新的进程,进行fuzz。
这里afl_fuzz进程与fork server是父子关系,fork server与目标程序的进程是父子关系。fork server使用waitpid()等待目标程序执行完成,然后通过pipe将执行状态返回给afl_fuzz。
fuzzer <-> target
在fuzz进行的过程中,还有一个问题需要解决:如何根据程序运行的状态来动态调整测试用例(test case mutateion)。在上面的分析中,我们已经知道afl_fuzz可以通过管道命令来获取目标程序的运行状态,但是仅仅知道程序的exit code并不能满足要求。因此,afl使用了共享内存的方法,实现afl_fuzz和目标程序之间的信息传递。
afl-fuzz在启动时,会调用setup_shm()来分配一块大小为MAP_SIZE的内存空间。1
2
3
4
5
6
7
8
9EXP_ST void setup_shm(void) {
shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600);
shm_str = alloc_printf("%d", shm_id);
// 判断运行的模式,将共享内存id写入环境变量
if (!dumb_mode) setenv(SHM_ENV_VAR, shm_str, 1);
// trace_bits为共享内存地址
trace_bits = shmat(shm_id, NULL, 0);
}
fuzz进行时,目标程序会读取环境变量,得到共享内存的id。1
2
3
4
5leaq .AFL_SHM_ENV(%rip), %rdi
CALL_L64("getenv")
testq %rax, %rax
je __afl_setup_abort
在每次执行目标程序前,afl_fuzz都会对共享内存进行清零1
2
3
4
5
6afl_fuzz.c
static u8 run_target(char** argv, u32 timeout) {
...
memset(trace_bits, 0, MAP_SIZE);
...
}
[1] check __afl_area_ptr
在目标程序中,首先会判断afl_area_ptr是否为空,若为空则跳转afl_setup1
2
3
4/* Check if SHM region is already mapped. */
movl __afl_area_ptr, %edx
testl %edx, %edx
je __afl_setup
[2] setup ptr
afl_setup首先会判断之前setup是否成功,若之前setup失败,则直接跳过。之后判断afl_global_area_ptr指针是否存在:
若存在->将afl_global_area_ptr存入rdx寄存器,并且调用afl_store
若不存在->调用afl_setup_first1
2
3
4
5
6
7
8__afl_setup:
cmpb $0, __afl_setup_failure(%rip)
jne __afl_return
movq __afl_global_area_ptr(%rip), %rdx
testq %rdx, %rdx
je __afl_setup_first
movq %rdx, __afl_area_ptr(%rip)
jmp __afl_store
首先来看afl_setup_first这段程序,开始保存了一些可能会被libcalls、getenv()影响的寄存器的值。1
2
3
4
5
6
7
8
9__afl_setup_first:
leaq -352(%rsp), %rsp
movq %rax, 0(%rsp)
movq %rcx, 8(%rsp)
movq %rdi, 16(%rsp)
...
...
movq %xmm14, 320(%rsp)
movq %xmm15, 336(%rsp)
之后先保存r12,再将栈指针保存到r12。之后分配了新的栈空间,进行栈对齐。
然后调用getenv得到环境变量AFL_SHM_ENV,若失败跳转afl_setup_abort1
2
3
4
5
6
7
8pushq %r12
movq %rsp, %r12
subq $16, %rsp
andq $0xfffffffffffffff0, %rsp
leaq .AFL_SHM_ENV(%rip), %rdi
CALL_L64("getenv")
testq %rax, %rax
je __afl_setup_abort
之后atoi字符串->数字,再调用shmat得到共享内存地址。若shmat失败,也会跳转afl_setup_abort。1
2
3
4
5
6
7
8movq %rax, %rdi
CALL_L64("atoi")
xorq %rdx, %rdx /* shmat flags */
xorq %rsi, %rsi /* requested addr */
movq %rax, %rdi /* SHM ID */
CALL_L64("shmat")
cmpq $-1, %rax
je __afl_setup_abort
最后存储共享内存的地址到%rdx寄存器和__afl_area_ptr中。1
2
3
4
5
6
7
8
9
10/* Store the address of the SHM region. */
movq %rax, %rdx
movq %rax, __afl_area_ptr(%rip)
#ifdef __APPLE__
movq %rax, __afl_global_area_ptr(%rip)
#else
movq __afl_global_area_ptr@GOTPCREL(%rip), %rdx
movq %rax, (%rdx)
#endif
movq %rax, %rdx
[3] afl_forkserver
首先会写入管道,通知父进程。1
2
3
4
5
6
7
8
9__afl_forkserver:
pushq %rdx
pushq %rdx
movq $4, %rdx
leaq __afl_temp(%rip), %rsi
movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi
CALL_L64("write")
cmpq $4, %rax
jne __afl_fork_resume
__afl_fork_wait_loop:
之后进入loop,读取管道中的内容,如果不为4,就会跳转afl_die。1
2
3
4
5
6
7__afl_fork_wait_loop:
movq $4, %rdx /* length */
leaq __afl_temp(%rip), %rsi /* data */
movq $" STRINGIFY(FORKSRV_FD) ", %rdi /* file desc */
CALL_L64("read")
cmpq $4, %rax
jne __afl_die
调用fork执行,成功跳转afl_fork_resume,失败跳转afl_die。1
2
3
4CALL_L64("fork")
cmpq $0, %rax
jl __afl_die
je __afl_fork_resume
将fork出的进程pid存入afl_fork_pid,同时通过管道发送。1
2
3
4
5 movl %eax, __afl_fork_pid(%rip)
movq $4, %rdx /* length */
leaq __afl_fork_pid(%rip), %rsi /* data */
movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */
CALL_L64("write")
之后等待子进程结束,将状态写入管道,如果返回的status小于等于0,就会跳到afl_die。将状态写入pipe后跳回loop,继续循环。1
2
3
4
5
6
7
8
9
10
11 movq $0, %rdx /* no flags */
leaq __afl_temp(%rip), %rsi /* status */
movq __afl_fork_pid(%rip), %rdi /* PID */
CALL_L64("waitpid")
cmpq $0, %rax
jle __afl_die
movq $4, %rdx /* length */
leaq __afl_temp(%rip), %rsi /* data */
movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi /* file desc */
CALL_L64("write")
jmp __afl_fork_wait_loop
####afl_fork_resume
关闭管道,恢复寄存器,跳转afl_store存储路径。1
2
3
4
5
6
7
8
9
10
11
12
13__afl_fork_resume:
movq $" STRINGIFY(FORKSRV_FD) ", %rdi
CALL_L64("close")
movq $" STRINGIFY((FORKSRV_FD + 1)) ", %rdi
CALL_L64("close")
popq %rdx
popq %rdx
movq %r12, %rsp
popq %r12
movq 0(%rsp), %rax
... ...
leaq 352(%rsp), %rsp
jmp __afl_store
__afl_die
出错则退出1
2
3__afl_die:
xorq %rax, %rax
CALL_L64("_exit")
__afl_store:
AFL是根据二元tuple(跳转的源地址+目标地址)来记录分支信息,从而获取目标程序的执行流程和代码覆盖情况。
cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
- 为了简化连接复杂对象的过程和保持XOR输出平均分布,当前位置是随机产生的。
- share_mem[]数组是一个调用者传给被instrument程序的64KB的共享内存区域,数组的元素是Byte。数组中的每个元素,都被编码成一个(branch_src, branch_dst),相当于存储路径的bitmap。这个数组的大小要应该能存2K到10K个分支节点,这样即可以减少冲突,也可以实现毫秒级别的分析。
这种形式的覆盖率,相对于简单的基本块覆盖率来说,对程序运行路径提供了一个更好的描述。以下面两个路径产生的tupes为例:
A -> B -> C -> D -> E (tuples: AB, BC, CD, DE)
A -> B -> D -> C -> E (tuples: AB, BD, DC, CE)
这更有助于发现代码的漏洞,因为大多数安全漏洞经常是一些没有预料到的状态转移,而不是因为没有覆盖那一块代码。- 最后一行右移操作是用来保持tuples的定向性。如果没有右移操作,A ^ B和B ^ A就没办法区别了,同样A ^ A和B ^ B也是一样的。Intel CPU缺少算数指令,左移可能会会导致级数重置为0,但是这种可能性很小,用左移纯粹是为了效率。
计算并储存代码命中位置,afl_prev_loc是前一次跳转位置,rcx为当前跳转位置,将afl_prev_loc的值与rcx的值进行交换,然后__afl_prev_loc右移一位。rdx为共享内存的地址。
1 | __afl_store: |
覆盖率计算
这里蓝色块代表程序执行过程中的基本块,黄色块代表相应的用于统计的探针代码,因而我们可以完整记录程序的执行路径,即:A -> C -> F -> H -> Z。另外,在AFL中为了更方便的描述边界(edge),将源基本块和目的基本块的配对组合称为tuple,即下图路径中有 4 个 tuple(AC,CF,FH,HZ)。

很自然,通过记录tuple信息就可以统计边界覆盖率了,AFL通过一个bitmap来记录这些信息,不过bitmap是以byte而非bit作为单位,因为程序还要记录tuple的命中数,而命中数又被划分成如下bucket:
References
- afl-fuzz-crash-exploration-mode
- Technical “whitepaper” for afl-fuzz
- afl-fuzz on different file systems
- Internals of AFL fuzzer - Compile Time Instrumentation
- Fuzzing random programs without execve()
- 漏洞挖掘技术之 AFL 项目分析
- afl-fuzz技术白皮书
- Fuzz之AFL
- http://zeroyu.xyz/2019/05/15/how-to-use-afl-fuzz/
- AFL内部实现细节小记
- AFL源码分析